
Domain Classification for Agent Autonomy
How do you know when an AI agent can act on its own, and when it needs human approval? I’ve been thinking about this question a lot while building Clawdia, my homelab automation agent.
The answer isn’t about how sophisticated the AI is. It’s about the problem domain itself.
A Framework I Wish I’d Known Earlier
Justin Cramer’s article Data Gravity and the Agentic AI Readiness Gap introduced me to Dave Snowden’s Cynefin framework, and it clicked immediately. The framework classifies problem domains into four categories based on cause-effect relationships:
- Clear — Best practices exist, cause-effect is obvious
- Complicated — Expert analysis needed, multiple valid approaches
- Complex — Patterns only visible in retrospect, probe-sense-respond
- Chaotic — Unknown unknowns, rapid containment needed
The insight: the domain determines what AI can do, not the AI’s sophistication.
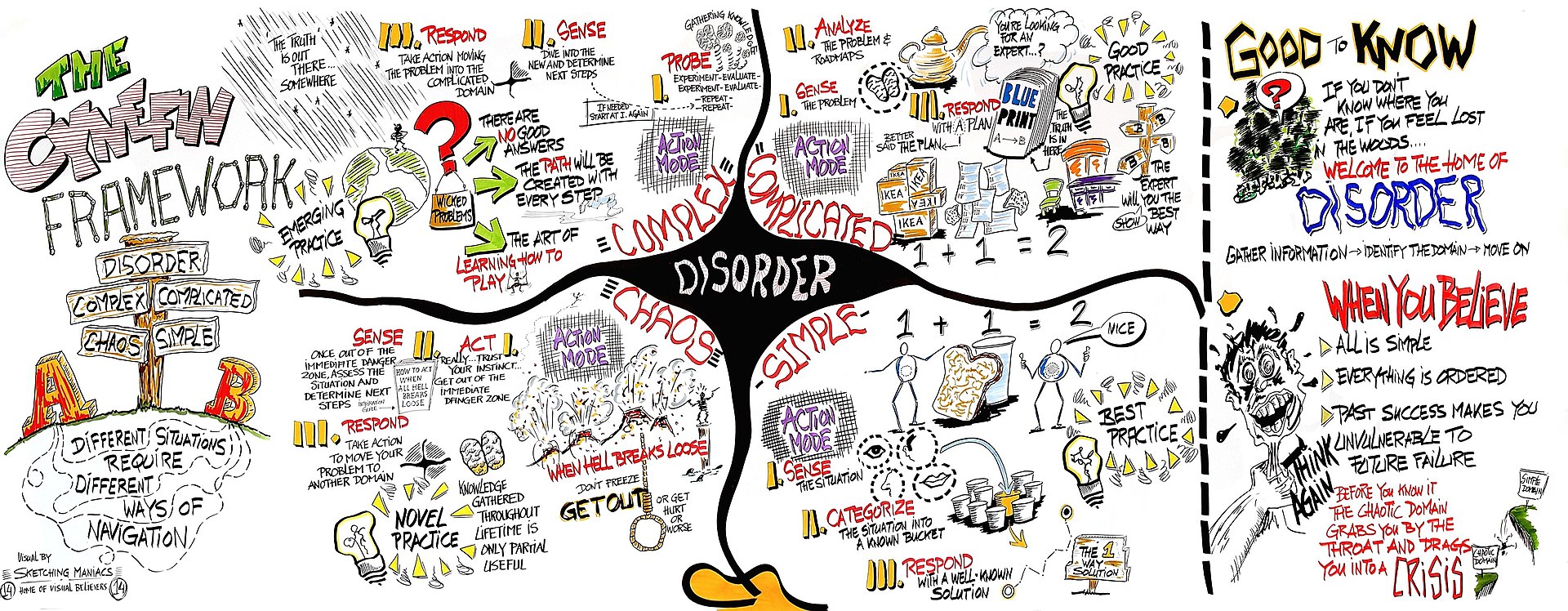
Sketch of the Cynefin framework by Edwin Stoop, via Wikipedia (CC BY-SA)
The Cynefin framework helps classify problem domains by cause-effect relationships.
Why This Matters for Homelabs
I used to route tasks to agents based on what they were about. Security things went to the security agent. Code things went to the code agent. Debugging went to the debug agent. This worked fine until it didn’t.
What I missed was that different aspects of the same problem fall into different domains. A container health check? Clear domain — autonomous agent can handle it. But that same container’s security hardening? Complicated domain — needs human approval for changes.
Cramer’s point about vendor responsibility resonated with me. He argues that vendors need to classify their problem domains so customers know where AI can safely operate. I realized I’m essentially the vendor of my own homelab automation — I should be doing this classification work.
What I Did
I built a domain classification registry at memory/semantic/problem-domains.md. Here’s what I found in my homelab:
Clear Domains — Autonomous Operation
Container status, backup verification, DNS resolution, log rotation. These have obvious cause-effect relationships. If a container is down, restart it. If backups fail, alert. No analysis needed.
My agent now operates autonomously here. It can restart containers, verify backups, and handle routine maintenance without asking permission.
Complicated Domains — Decision Support
Security hardening, performance tuning, container orchestration, disaster recovery planning. These require expertise. There are multiple valid approaches, and the right choice depends on context.
The agent proposes solutions, but I have to approve changes. It’s decision support, not autonomous operation.
Complex Domains — Probabilistic Prediction
Workload prediction, failure cascades, cost optimization. These are emergent — patterns only become clear after the fact.
The agent can make predictions with confidence intervals, but I interpret the uncertainty. There’s no right answer, just better or worse probability estimates.
Chaotic Domains — Rapid Containment
Novel attack vectors, hardware failures, upstream bugs. These are unknown unknowns.
The agent’s job here is containment and escalation. Detect, contain, document, alert me. Pattern discovery happens after stabilization, when the domain shifts from Chaotic toward Complex.
The Practical Benefit
Before this classification, I’d get woken up at 3am for routine stuff that could’ve waited, and then discover the agent had been silently failing on something important for weeks. Now:
- Clear domain issues get handled automatically and logged
- Complicated domain issues wait for my review with recommendations
- Complex domain issues come with uncertainty estimates
- Chaotic domain issues escalate immediately with containment actions
The agent knows its bounds. I know what I’m signing up for when I approve a task. And most importantly, I’m building a knowledge base of which domains can shift toward greater autonomy over time.
What Surprised Me
The classification work itself was easier than I expected. Most domains fell into obvious categories once I started thinking about them. The hardest part was just remembering to ask the question.
Some domains shift over time. Chaotic domains become Complex as patterns emerge. Complex domains become Complicated as we learn more. Complicated domains can even become Clear once best practices crystallize. Tracking these shifts teaches me where my automation is maturing.
Where I’m Going Next
I’m adding Cynefin classification to my agent routing logic. When a task comes in, the system checks the domain classification and routes accordingly:
- Clear → Autonomous execution with logging
- Complicated → Recommendation + human approval
- Complex → Probabilistic analysis with confidence intervals
- Chaotic → Containment + immediate escalation
I’m also adding domain classification to my learning log schema. When something goes wrong, I record the domain. Over time, I’ll see which domains have the most incidents and whether domains are shifting in expected directions.
Try This
If you’re running agents in your homelab or business, try classifying your problem domains:
- List your recurring automation tasks
- Ask: Is cause-effect obvious? (Clear) Requires analysis? (Complicated) Only visible in retrospect? (Complex) No discernible pattern? (Chaotic)
- Route agent behavior based on classification
- Track when domains shift
The classification work isn’t glamorous. But it’s foundational. And it beats finding out your agent is operating in domains it has no business being in.
Further reading: The Cynefin framework was developed by Dave Snowden. Justin Cramer’s article applies it specifically to AI readiness gaps in logistics, which is where I first encountered it. My full domain classification registry is at memory/semantic/problem-domains.md in my OpenClaw workspace.
